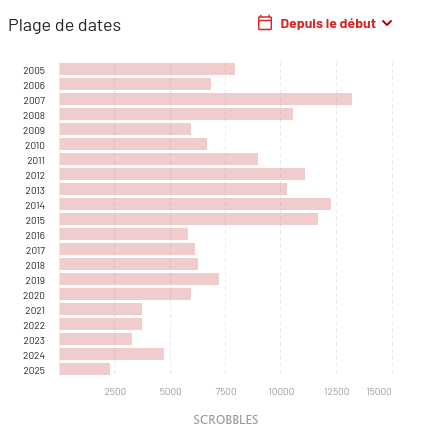
Ça fait quelques années
maintenant que j'utilise avec joie et bonheur /e/OS sur mes téléphones. La
seule petite déception jusque-là aura été le remplacement de TWRP par leur bouse recovery maison
sans me demander mon avis (ça fait toujours plaisir)
Bien sûr j'ai aussi été déçu par l'arrêt du support de mon vieux Samsung Galaxy A5, mais bon il y a un moment où on peut plus lutter.
Quand je me suis enfin décidé à lui faire prendre sa retraite, la question de l'OS ne s'est pas posée longtemps : le Fairphone 6 qui l'a remplacé avait une version OFFICIELLE sous /e/OS.
Malheureusement depuis il y a eu plusieurs déconvenues :
- Les manques originels (reconnaissance faciale, et surtout, le Always-On-Display) sont devenus vraiment pesants. Passe encore pour le déverrouillage par caméra, accessoire et sans doute pas tip-top pour la vie privée, mais le Always-On-Display, vous savez ce truc magique qui transforme votre téléphone en montre qui affiche l'heure sans avoir à l'allumer, est pour ma part devenu indispensable. Je pensais naïvement qu'll s'agissait d'un patch non appliqué par manque de temps ou de ressources, mais les versions s'enchaînent et ce n'est toujours pas corrigé. J'ai bien entendu contourné ce manque en installant un soft qui fait ça, mais comme ce n'est pas natif, ce n'est pas "fluide" (par exemple, la sonnerie d'un minuteur n'allume pas l'écran comme une solution native le ferait... Pratique)
- J'ai appris ensuite que l'App Lounge, l'application phare de /e/OS, n'étais pas super fiable, et en effet elle a zappé plusieurs mises à jour, et qu'il fallait plutôt utiliser Aurora Store (un comble)
- Et, last but not least, Fairphone ayant sorti sa version d'Android 16 le mois dernier, je m'attendais à ce que /e/OS suive. Ce qu'il a fait d'ailleurs une semaine plus tard avec une version supportant Fairphone 4, et... Fairphone 5 (!)
Tout cela commence à faire beaucoup, et les petits compromis que j'ai fait commencent à être fatigants, surtout quand l'OS est systématiquement un cran en dessous de tout ce qui se fait ailleurs. Après tout, un bon AdAway couplé à un OpenVPN font tout aussi bien le boulot.
Edit 3 mai 2026 : Après quelques galères liées au lecteur d'empreintes, c'est fait.